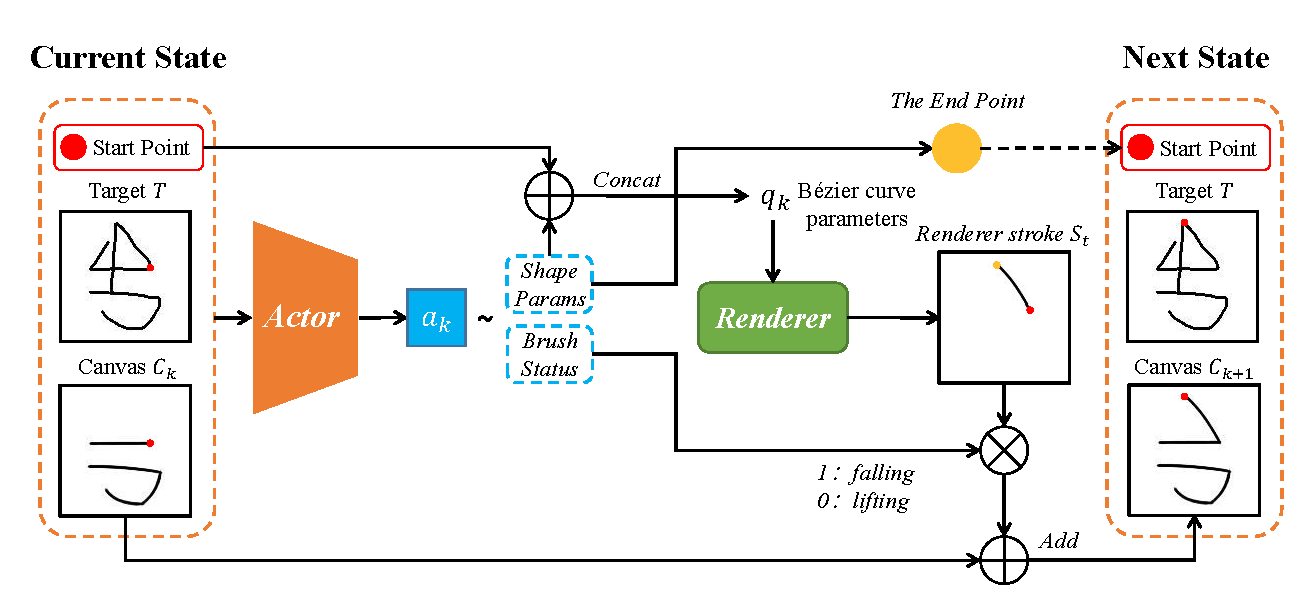
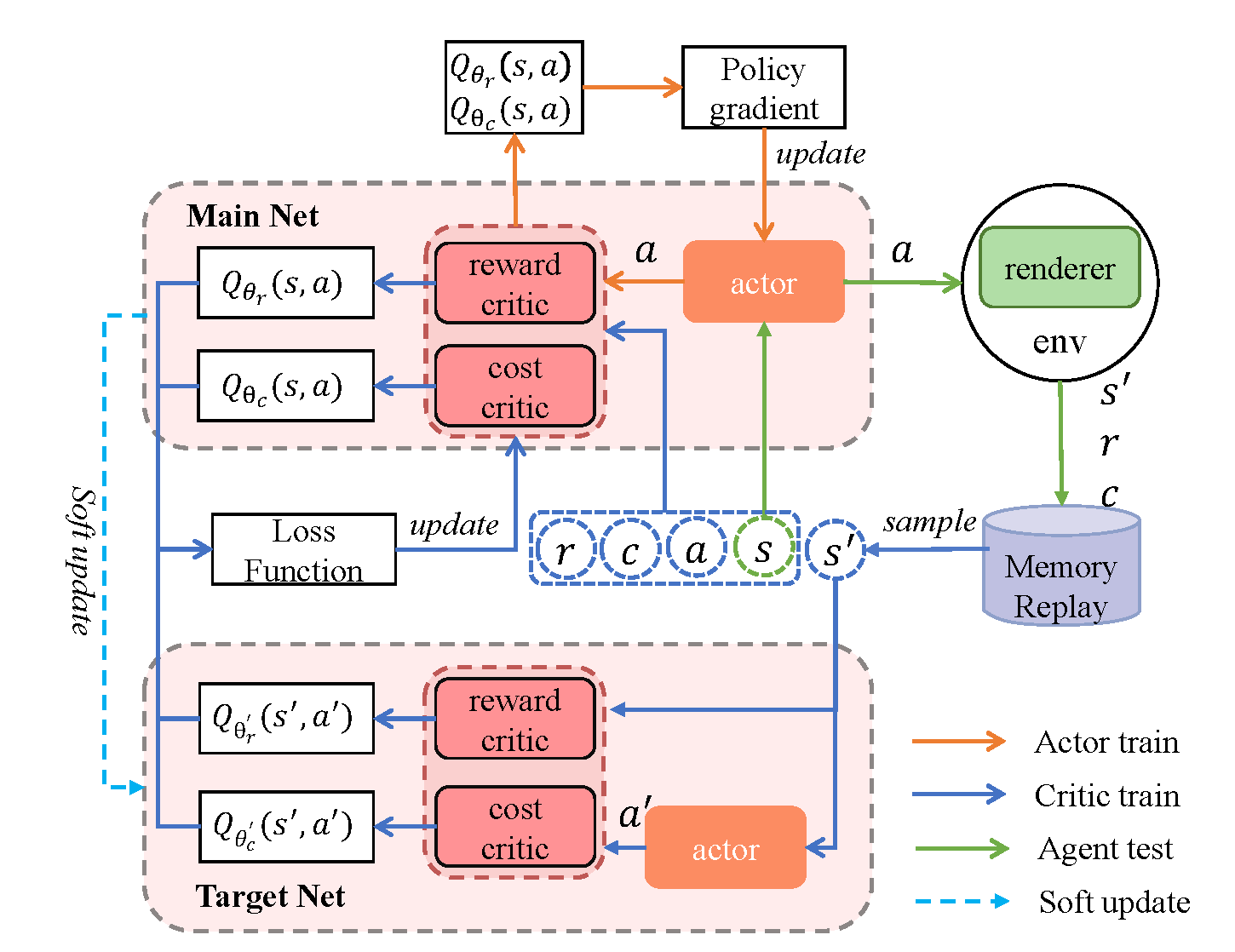
Sketch reconstruction aims to recreate a target sketch by generating a sequence of vector strokes. Traditional methods often focus solely on the visual similarity of the final drawing while neglecting the stroke generation process, resulting in redundant strokes and disordered sequences. To address this limitation, we propose a sketch agent framework based on a Constrained Markov Decision Process (CMDP). To ensure the spatial continuity between adjacent strokes and get closer to the human drawing process, we introduce a hybrid action space for the sketching agent. Furthermore, we carefully design reward and cost functions to guide the agent in achieving efficient sketch reconstruction using more concise strokes while maintaining visual fidelity. Unlike existing methods that rely on supervised learning, our framework adopts a self-supervised learning paradigm, freeing it from the dependence on paired vector label data. Experimental results on the MNIST and QuickDraw datasets demonstrate the significant advantages of our approach in various sketch reconstruction tasks. Ablation studies further validate the effectiveness of our method in reducing the number of strokes and optimizing their sequence.
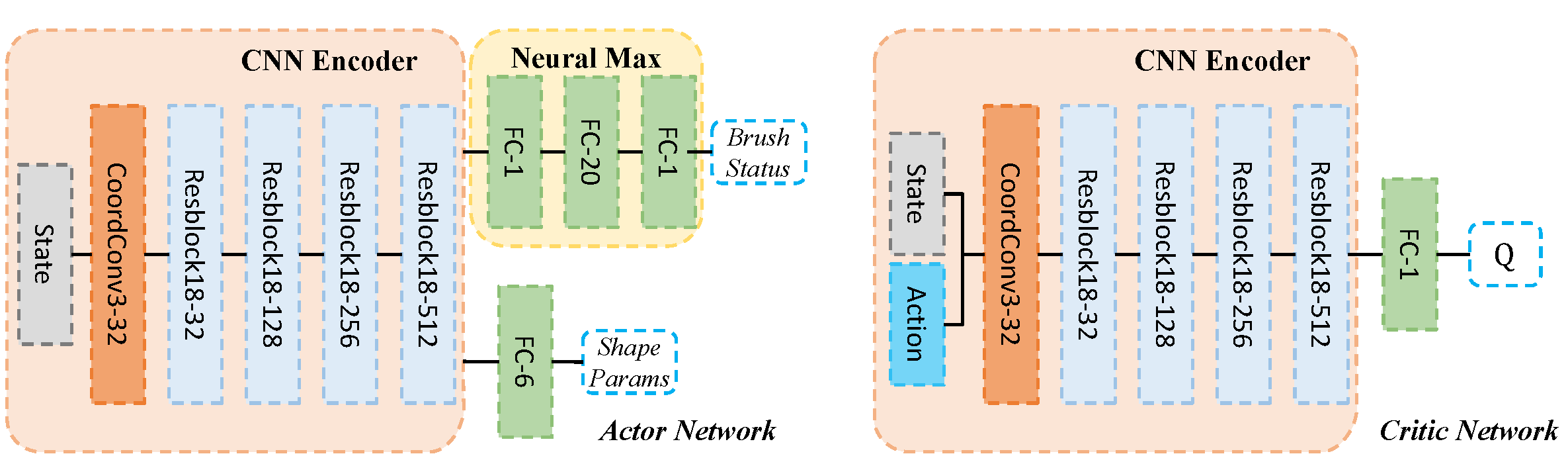
We evaluate our Sketching Agent on two datasets: MNIST and QuickDraw. MNIST comprises 70 000 handwritten digits (60 000 for training, 10 000 for testing), each a 28×28 grayscale image. QuickDraw contains 50 million sketches across 345 categories; we randomly sample 50 000 for training, 5 000 for validation, and 5 000 for testing, discarding category labels. All images are resized to 128×128; QuickDraw sketches are further augmented by scaling to 256×256 and extracting four random 128×128 crops. Both the actor and critic networks use ADAM (initial learning rates 1 × 10⁻⁴ and 1 × 10⁻³, step‐decay scheduler), a batch size of 48, and a replay buffer of 40 000. We train for 40 000 episodes on MNIST (max 10 steps per episode) and 20 000 on QuickDraw (max 40 steps), with discount factor γ=0.95. On a single NVIDIA 3090 Ti, training takes ~7 h for MNIST and ~48 h for QuickDraw. Episodes terminate when the step limit is reached or the pen is lifted twice consecutively.













































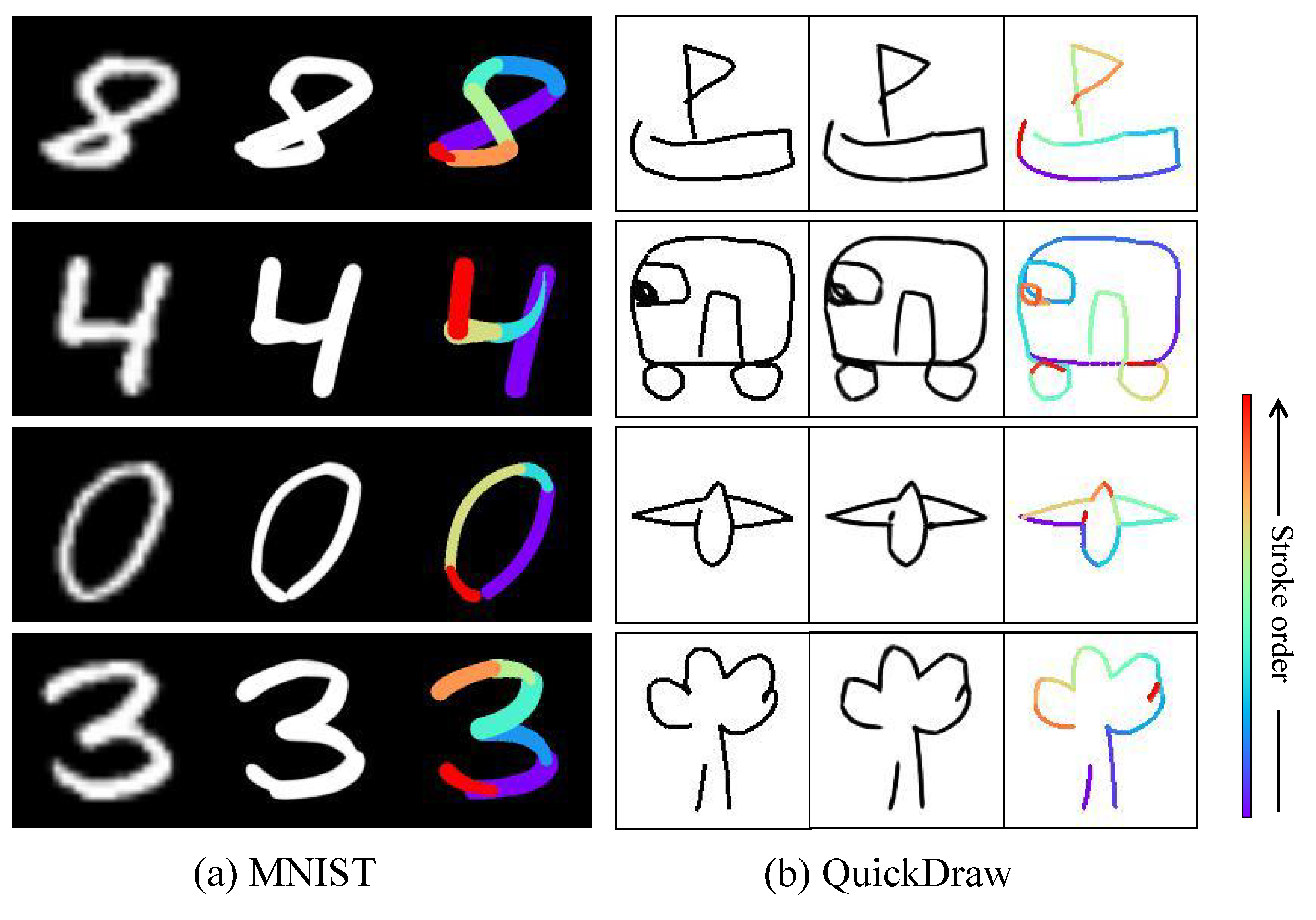
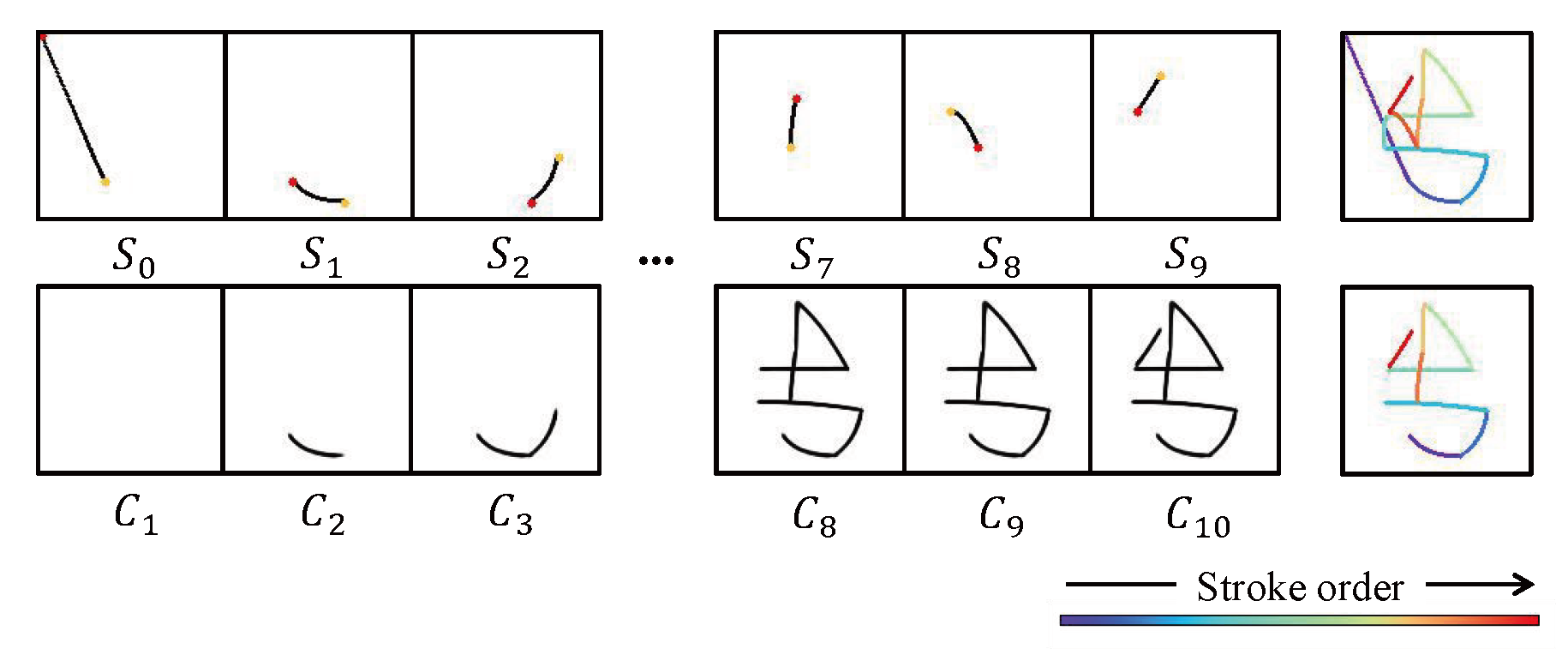
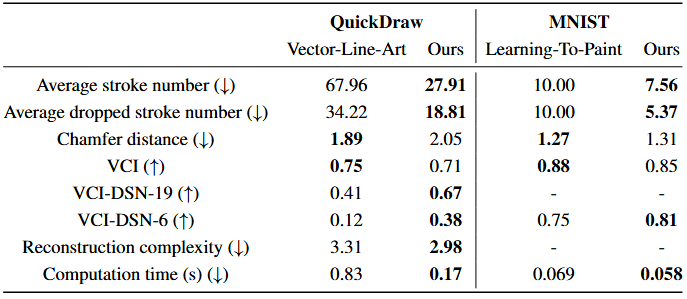
Vector-Line-Art is tailored for line-art images, while Learning‑To‑Paint is designed for complex images. Therefore, we conducted comparative evaluations of these two methods on the QuickDraw and MNIST datasets. Figure 6 shows that, compared to Learning‑To‑Paint, the Sketching Agent can reconstruct sketches using continuous, human‑like strokes.

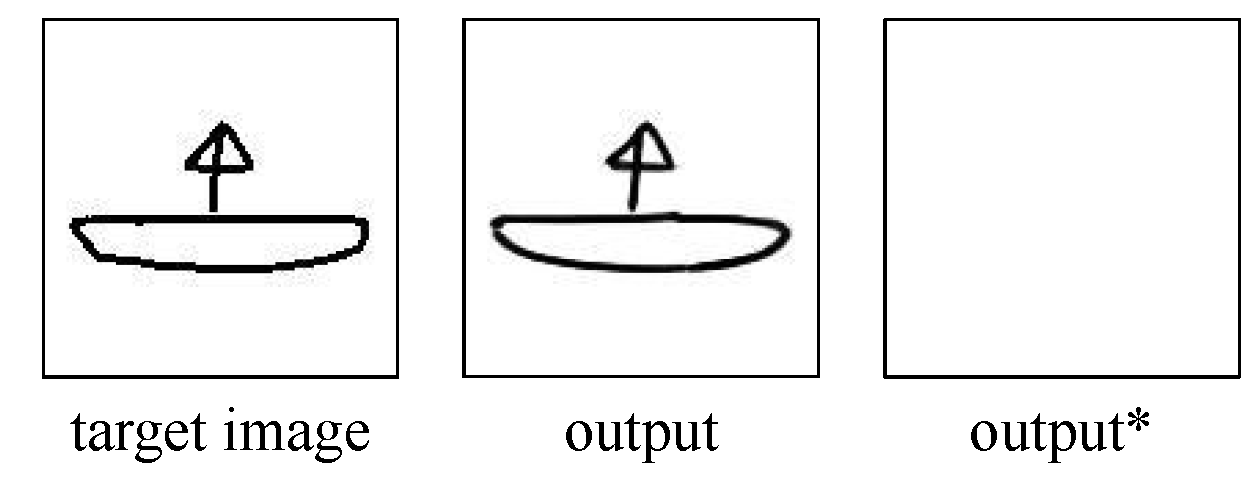
Figure 7 demonstrates that our method, by employing more succinct continuous strokes, reconstructs the target image while preserving the same visual appearance.
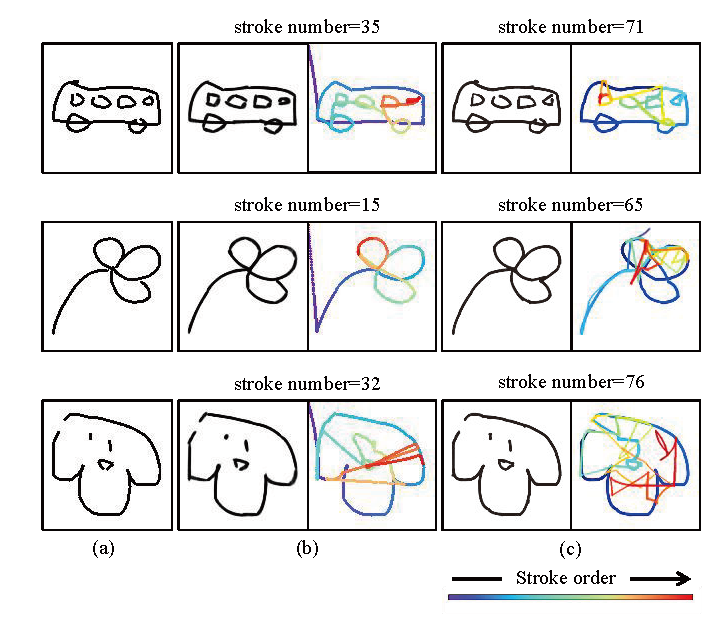
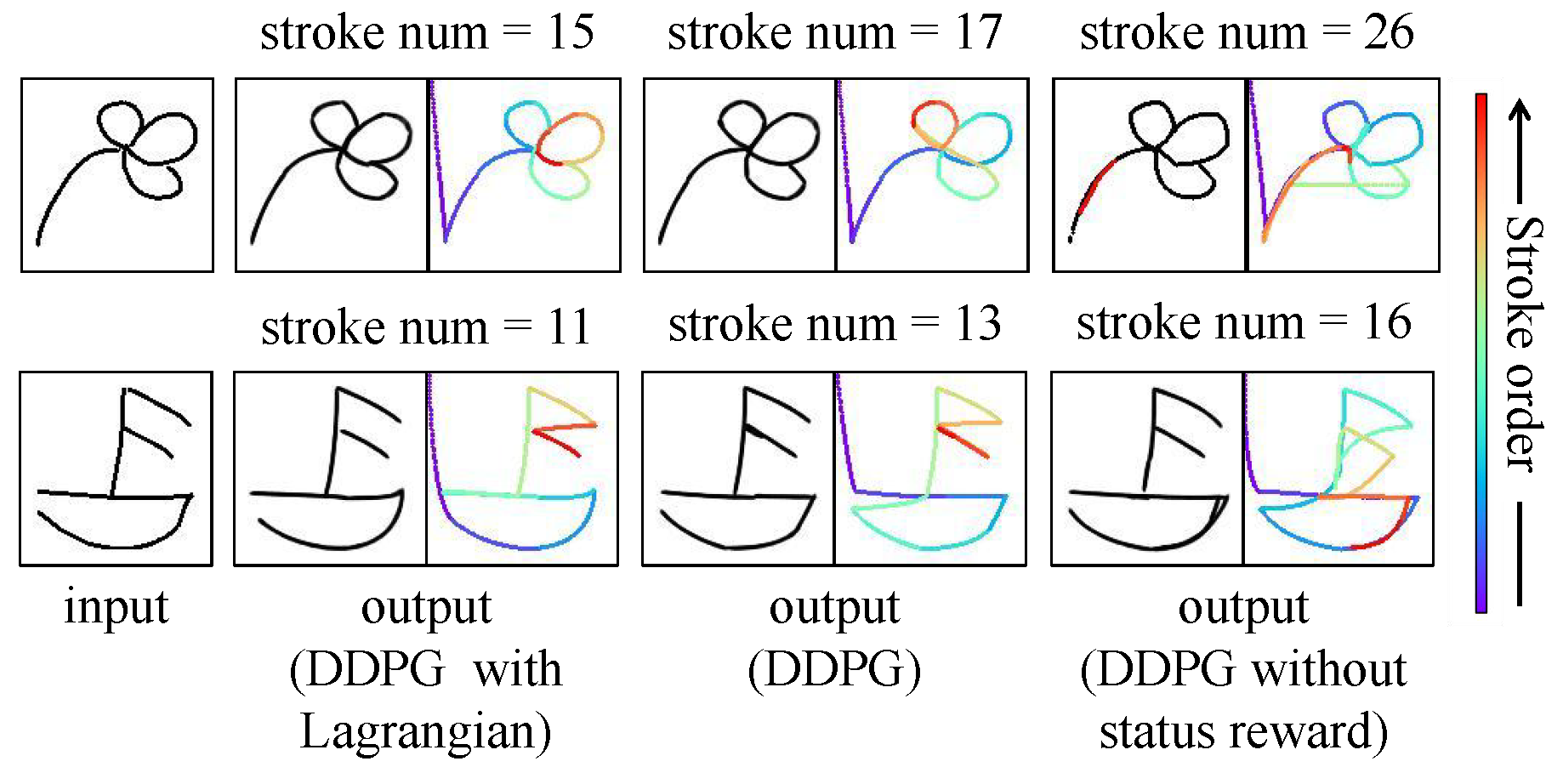
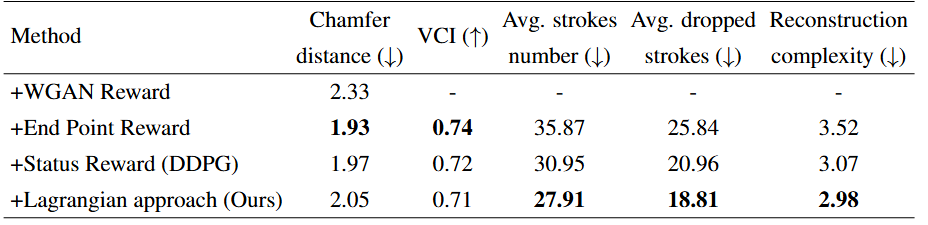
Results of ablation experiments based on QuickDraw.